【Go源码】map类型与实现
Go源码-map类型与实现
go项目分支:release-branch.go1.5
代码地址:https://github.com/golang/go/blob/release-branch.go1.10/src/runtime/hashmap.go
本文主要介绍了go语言map类型的使用和内部实现过程,代码是基于go1.5分支为例,与最新的版本可能会有出入,希望大家举一反三,有说的不正确的希望能指出谢谢!本文重点在map的结构和查找的过程,插入和删除的过程涉及扩展和收缩代码比较绕,后续会继续深入。
常用操作
var m map[string]interface{} // 声明一个map
m := map[string]interface{} // 定义一个map
m := make(map[string]interface{},3) // 初始化一个map,并设置元素容量,1.5版本未支持容量设置,但最新的1.10已支持,hashmap会自动根据负载因子6.5设置合适的桶大小.至于负载因子为什么为6.5,在hashmap.go文件注释中有说明,这是作者通过实践得出的经验值。
m[k] = v // 设置值
v := m[k] // 取值
v,ok := m[k] // 取值,带结果判断 v:结果 ok:返回bool判断结构是否存在
for k,v := range m {} // 迭代
类型结构
HashMap结构
type hmap struct {
count int // 表中的元素总量
flags uint8 // 当前桶标志,1:使用的是buckets,2:使用的是oldbuckets
B uint8 // 桶总大小的对数
hash0 uint32 // 哈希函数种子
buckets unsafe.Pointer // 桶队列的首地址,2的B次方长度的队列作为桶,当表中元素count==0的时候指针有可能为nil
oldbuckets unsafe.Pointer // 前半部分桶的队列指针
nevacuate uintptr // 收缩操作计数器 ()
overflow *[2]*[]*bmap // 溢出区,其中 overflow[0]为buckets的溢出区,overflow[1]为oldbuckets的溢出区。好处:1.减少hash表的长度 2.可以把指针存到一个数组中
}
Go的Map内部就是一般的HashMap结构,数据均衡存储到多个桶中。通过大量指针与偏移量操作实现数据的插入和查找。

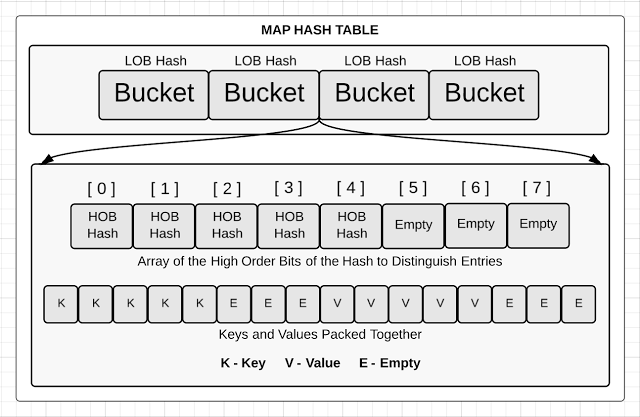
桶内部结构
type bmap struct {
tophash [bucketCnt]uint8
}
操作实现
创建
// t: map的类型
// hint: 容量
// h: 指定hmap指针,如果存在则直接在该地址创建
// bucket: 指针bucket指针,如果存在直接把该桶地址作为首个桶
func makemap(t *maptype, hint int64, h *hmap, bucket unsafe.Pointer) *hmap {
// 容量检查-编译过程长度检查
if sz := unsafe.Sizeof(hmap{}); sz > 48 || sz != uintptr(t.hmap.size) {
println("runtime: sizeof(hmap) =", sz, ", t.hmap.size =", t.hmap.size)
throw("bad hmap size")
}
// 容量检查-容量不能大于int64长度
if hint < 0 || int64(int32(hint)) != hint { panic("makemap: size out of range") }
// 元素类型检查
mapzero(t.elem)
// 根据元素容量hint和负载因子找到合适的桶队列大小B
B := uint8(0)
for ; hint > bucketCnt && float32(hint) > loadFactor*float32(uintptr(1)<<B); B++ {
}
// 对桶队列分配内存
buckets := bucket
if B != 0 {
buckets = newarray(t.bucket, uintptr(1)<<B)
}
// 初始化HashMap对象
if h == nil {
h = (*hmap)(newobject(t.hmap))
}
h.count = 0
h.B = B
h.flags = 0
h.hash0 = fastrand1()
h.buckets = buckets
h.oldbuckets = nil
h.nevacuate = 0
return h
}
查找
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool) {
// 此处省略一些边界和条件判断
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0)) // 哈希函数
m := uintptr(1)<<h.B - 1
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + (hash&m)*uintptr(t.bucketsize))) // 通过对key进行哈希找到所在桶的末地址,针对.Buckets 这个地方写的有点啰嗦,可以考虑先对.oldbuckets做运算如果存在直接跳过.Buckets的运算
if c := h.oldbuckets; c != nil {
oldb := (*bmap)(unsafe.Pointer(uintptr(c) + (hash&(m>>1))*uintptr(t.bucketsize))) // 通过对key进行哈希找到所在桶的末地址,针对oldBuckets
if !evacuated(oldb) {
b = oldb
}
}
top := uint8(hash >> (ptrSize*8 - 8)) // 移向桶组数的首地址
if top < minTopHash {
top += minTopHash
}
for {
// 在topHash桶队列中查找该桶
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey {
k = *((*unsafe.Pointer)(k))
}
if alg.equal(key, k) {
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
if t.indirectvalue {
v = *((*unsafe.Pointer)(v))
}
return v, true
}
}
// 在溢出区返回该元素
b = b.overflow(t)
if b == nil {
return unsafe.Pointer(t.elem.zero), false
}
}
}
总结
- Go的map类型由Hashmap实现,底层由一系列[8]int8的桶数组构成,总长度为 2^B
- map的负载因子为6.5
- 查找的过程:通过对key进行取mod找到桶地址,从桶队列
topHash中定位到该桶,通过对桶首地址加入元素的偏移量找到该元素。当topHash桶未查找成功,从溢出区返回具体元素指针.